Одновременно с этим компания StarWind объявила также о том, что решение StarWind iSCSI SAN 6.0 для хранения виртуальных машин VMware vSphere также становится бесплатным (при использовании дисковых ресурсов до 128 ГБ), при этом доступны все возможности продукта для обеспечения отказоустойчивости хранилищ. Об этом подробно написано в документе "StarWind iSCSI SAN Free. The difference between free and paid editions".
Для тех, кому лень открывать документ на английском, приводим обновленное сравнение бесплатного и коммерческого изданий StarWind iSCSI SAN 6.0:
StarWind iSCSI SAN
Free Edition - бесплатно
Коммерческие издания (в зависимости от лицензируемой емкости 1 ТБ - 512 ТБ)
Компоненты продукта
Лицензируемая емкость хранилищ
Не ограничена для одного узла и ограничение 128 ГБ для HA-конфигурации (на узел)
1 ТБ - 512 ТБ
Размер кэша
512 МБ
Не ограничен
Централизованное управление
StarWind Console
StarWind Console
Число серверов, входящее в лицензию
2
2 или 3
Число одновременных соединений по iSCSI к хранилищам
Кроме того, не так давно были воплощены в жизнь такие полезные службы vSphere для работы с SSD-накопителями, как SSD Monitoring (реализуется демоном smartd) и Swap to SSD (использование локальных дисков для файлов подкачки виртуальных машин). Однако функции кэширования на SSD реализованы пока совсем в базовом варианте, поэтому сегодня вам будет интересно узнать о новой технологии Virtual Flash (vFlash) для SSD-накопителей в VMware vSphere, которая была анонсирована совсем недавно.
Эта технология, находящаяся в стадии Tech Preview, направлена на дальнейшую интеграцию SSD-накопителей и других flash-устройств в инфраструктуру хранения VMware vSphere. Прежде всего, vFlash - это средство, позволяющее объединить SSD-ресурсы хост-серверов VMware ESXi в единый пул, используемый для задач кэширования, чтобы повысить быстродействие виртуальных машин. vFlash - это фреймворк, позволяющий сторонним вендорам SSD-накопителей и кэш-устройств использовать собственные алгоритмы для создания модулей обработки кэшей виртуальных машин (плагины vFlash Cache Modules). Будет реализован и собственный базовый алгоритм VMware для работы с кэшем.
Основная мысль VMware - предоставить партнерам некий API для их flash-устройств, за счет которого виртуальные машины будут "умно" использовать алгоритмы кэширования. Для этого можно будет использовать 2 подхода к кэшированию: VM-aware caching и VM-transparent caching:
VM-aware Caching (vFlash Memory)
В этом режиме обработки кэширования флэш-ресурс доступен напрямую для виртуальной машины, которая может использовать его на уровне блоков. В этом случае на уровне виртуального аппаратного обеспечения у виртуальной машины есть ресурс vFlash Memory определенного объема, который она может использовать как обычный диск в гостевой ОС. То есть, приложение или операционная система должны сами думать, как этот высокопроизводительный ресурс использовать. Можно вообще использовать его не как кэш, а как обычный диск, хотя идея, конечно же, не в этом.
VM-transparent Caching (vFlash Cache)
В этом случае виртуальная машина и ее гостевая ОС не знают, что на пути команд ввода-вывода находится прослойка в виде flash-устройств, оптимизирующих производительность за счет кэширования. В этом случае задача специализированного ПО (в том числе от партнеров) - предоставить оптимальный алгоритм кэширования. В этом случае будет доступна настройка следующих параметров кэша:
Гарантированный объем (Reservation size)
Выбор программного модуля-обработчика (vFlash Cache Module)
Размер блока (настраивается в зависимости от гостевой ОС)
Что делать с кэшем при перемещении виртуальной машины посредством vMotion (перенести вместе с ней или удалить)
При vMotion сервер vCenter будет проверять наличие необходимых ресурсов кэширования для виртуальной машины на целевом хосте ESXi. Для совместимости с технологией VMware HA, виртуальная машина должна будет иметь доступные vFlash-ресурсы на хранилищах хостов в случае сбоя (соответственно, потребуется эти ресурсы гарантировать).
В целом vFlash в VMware vSphere обещает быть очень перспективной технологией, что особенно актуально на волне роста потребления SSD-накопителей, постепенно дешевеющих и входящих в повсеместное употребление.
Компания HP обновила Firmware для своих серверов HP ProLiant, доступное для гипервизора VMware ESXi 5.0 и более поздних версий. Обновление доступно по этой ссылке.
Процесс обновления Firmware проходит из сервисной консоли серверов VMware ESXi, при этом предварительными требованиями является наличие следующих компонентов:
Мы уже писали о некоторых функциях утилиты esxcli в VMware vSphere, которая работает с различными пространствами имен, такими как network, storage, hardware и прочими. Сегодня мы хотим остановиться на новых функциях по управлению устройствами ввода-вывода I/O Device Management (IODM), пространство имен для которых появилось в VMware vSphere 5.1. Цель этих новых инструментов - дать администратору инструменты для понимания уровня, на котором происходят проблемы с хранилищем в сети SAN (см. тут).
Это новое пространство имен выглядит вот так:
esxcli storage san
Например, мы хотим сделать Reset для FC-адаптера:
esxcli storage san fc reset -A vmhba3
А потом посмотреть его лог, который включает в себя информацию о таких событиях, как разрыв соединения:
esxcli storage san fc events get
Можно собрать статистику по iscsi-адаптеру командой:
esxcli storage san iscsi stats get
Кроме того, в VMware vSphere 5.1 появились функции мониторинга твердотельных накопителей - SSD Monitoring, реализуемые метриками, которые собирает каждые полчаса демон S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology). Находятся стандартные плагины в /usr/lib/VMware/smart_plugins (кстати, вендоры дисковых устройств могут добавлять туда свои плагины вместо имеющихся generic-плагинов). Надо также отметить, что эти метрики не передаются в vCenter и доступны только через esxcli.
Посмотреть статистики SSD-дисков можно командой:
esxcli storage core device smart get -d naa.xxxxxx
Жирным выделены метрики, которые могут оказаться полезными. Параметр Reallocated Sector Count не должен сильно увеличиваться со временем для исправных дисков. Когда дисковая подсистема получает ошибку read/write/verification для сектора, она перемещает его данные в специально зарезервированную область (spare area), а данный счетчик увеличивается.
Media Wearout Indicator - это уровень "жизни" вашего SSD-диска (для новых дисков он должен отображаться как 100). По мере прохождения циклов перезаписи диск "изнашивается" и данный счетчик уменьшается, соответственно, когда он перейдет в значение 0 - его жизнь формально закончится, исходя из рассчитанного для него ресурса. Кстати, этот счетчик может временно уменьшаться при интенсивных нагрузках диска, а потом восстанавливаться со временем, если средняя нагрузка на диск снизилась.
В этой статье мы расскажем о новых возможностях, которое приобрело это средство номер 1 для создания iSCSI-хранилищ под виртуализацию Hyper-V.
Итак, что нового:
Много улучшений High Availability. Во-первых, улучшился уровень юзабилити - теперь интерфейсы выглядят проще и работают быстрее. Многие операции снабжены мастерами. Во-вторых, улучшился движок HA - теперь можно производить операции add, remove
и switch для HA-узла без вывода его в режим "Offline".
Новые функции HA-устройств. Теперь в качестве HA-устройств могут быть использованы такие девайсы как deduplicated, thin-provisioned IBV или
DiskBridge. Это означает, что теперь доступна функциональность дедупликации, thin provisioning, снапшоты и прочее для HA-устройств.
Улучшения дедупликации:
Asynchronous replication of deduplicated data - теперь данные для репликации по медленным каналам (WAN) могут передаваться асинхронно, что позволяет использовать решение в DR-сценариях. Кроме того, теперь любой тип устройства может быть целевым для репликации.
Deletion of unused data - неиспользуемые блоки, появляющиеся на дедуплицируемом хранилище, записываются актуальными данными, что позволяет использовать пространство более эффективно.
Decreased memory usage - в этой версии StarWind Native SAN на 30% снижены требования к памяти сервера. Теперь при использовании блоков 4 KB только 2 МБ оперативной памяти требуется на 1 ГБ хранимых данных.
Полная поддержка Windows Server 2012.
Скачать StarWind Native SAN for Hyper-V 6.0 можно по этой ссылке. И напоминаем, что у этого решения есть полнофункциональная бесплатная версия.
Таги: StarWind, iSCSI, SAN, Update, Hyper-V, Storage, HA
Некоторые из вас, вероятно, видели документ, называющийся "VMFS File Locking and Its Impact in VMware View 5.1", доступный у нас вот тут. Он вкратце рассказывает о нововведении в VMware View 5.1 - теперь для пулов связанных клонов (Linked Clones) можно использовать кластеры до 32-х хостов, а не 8 как раньше. Но работает это только для тех окружений, где реплика базового образа размещена на NFS-хранилище, для VMFS же хранилищ ограничение осталось тем же самым - кластер из максимум 8 хостов. Давайте разбираться, почему это так.
Во-первых, посмотрим как выглядит классическая структура связанных клонов в инсталляции VMware View:
В пуле связанных клонов, который мы можем построить с помощью VMware View Composer, находится создаваемый и настраиваемый базовый образ (может быть со снапшотом), из которого создается реплика этой ВМ (Replica), на базе которой из дельта-дисков строятся уже конечные десктопы пользователей. При этом данные реплики используются одновременно всеми связанными клонами, которые располагаются на хост-серверах ESXi кластера.
Теперь напомним, что мы уже рассматривали типы блокировок (локов) в кластерной файловой системе VMFS. Однако там рассмотрены не все блокировки, которые могут быть применены к файлам виртуальных дисков. Мы рассматривали только эксклюзивную блокировку (Exclusive Lock), когда только один хост может изменять VMDK-файл, а все остальные хосты не могут даже читать его:
Такие блокировки используются в традиционном окружении инфраструктуры виртуализации для серверной нагрузки в виртуальных машинах. Очевидно, что такие блокировки не подходят для доступа к данным файла виртуального диска реплики VMware View.
Поэтому есть и другие типы блокировок. Во-первых, Read-Only Lock (в этом режиме все хосты могут читать один VMDK, но не могут менять его):
Во-вторых, Multi-Writer Lock:
В режиме такой блокировки сразу несколько хостов могут получить доступ к VMDK-файлу на общем хранилище VMFS в режиме Read/Write. При использовании инфраструктуры связанных клонов на хранилище применяются локи типа Read-Only Lock и Multi-Writer Lock, что требует одновременного доступа нескольких хостов ESXi к одному файлу. Естественно, где-то в локе должны храниться данные о том, какие хосты используют его.
А теперь посмотрим на внутренности лока. Они как раз и содержат все UID (User ID) хостов, которые работают с VMDK-файлом, в структуре "lock holders". Надо отметить, что для работы автоматической процедуры обновления лока необходимо, чтобы его размер был равен одному сектору или 512 байтам. А в этот объем помещается только 8 этих самых UID'ов, а девятый уже не влезает:
Напомню, что мы говорим про диск реплики, который необходим сразу всем хостам кластера с виртуальными ПК этого пула. Поэтому, как и раньше, в VMware View 5.1 нельзя использовать для реплики, размещенной на томе VMFS, кластер из более чем восьми хост-серверов VMware ESXi.
Однако можно поместить реплику на том NFS. По умолчанию протокол NFS не поддерживает file locking, однако поддерживает механизм Network Lock Manager
(NLM), который использует схему блокировок "advisory locking":
В этой схеме клиенты файла NFS могут координировать между собой совместный доступ к файлу (в нашем случае - VMDK). При этом никакого лимита на 8 хостов в этом механизме нет. Однако раньше в VMware View не позволялось использовать более 8 хостов в кластере для пула связанных клонов.
Теперь это сделать можно и, во многих случаях, даже нужно, выбрав NFS-хранилище для пула Linked Clone:
Там собственно и будут раскрыты все новые возможности этого решения, у которого есть еще и полнофункциональная версия StarWind Native SAN for Hyper-V Free Edition, ограниченная лишь объемом хранилища (128 ГБ).
Многие знают компанию StarWind как производителя средства номер 1 для создания отказоустойчивых хранилищ StarWind iSCSI SAN под виртуальные машины VMware vSphere. Не так давно вышла обновленная версия StarWind iSCSI SAN 6.0 этого решения. Но, как известно, StarWind предлагает еще и отказоустойчивое решение для серверов Hyper-V.
15 ноября компания StarWind сделала 3 важных анонса, которые вам будут, безусловно, интересны:
Во-первых, вышла новая версия продукта под гипервизор Microsoft Hyper-V: StarWind Native SAN 6.0 (документ с описанием новых возможностей вот тут)
Во-вторых, вышла финальная версия решения для резервного копирования виртуальных машин на VMware vSphere, поставляемого в виде плагина - VMware Backup Plug-in. Теперь продукт полностью поддерживает новую платформу VMware vSphere 5.1.
Поскольку из этих новостей самая интересная - третья, то мы расскажем о бесплатном продукте StarWind Native SAN for Hyper-V Free edition. Он позволяет построить небольшой, но отказоустойчивый кластер хранилищ из двух серверов Microsoft Hyper-V на основе протокола iSCSI, без необходимости вложений во что бы то ни было - серверы под СХД или лицензии. Можно взять 2 обычных хост-сервера Hyper-V и забацать кластер.
Давайте взглянем на отличие бесплатного продукта от его платной версии:
StarWind Native SAN for Hyper-V
Free Edition - бесплатно
Small Business
Midsize Business
Enterprises
Компоненты продукта
Лицензируемая емкость хранилищ
Не ограничена
(HA-хранилище ограничено размером 128 ГБ)
1 ТБ / 2 ТБ (HA)
4 ТБ / 8 ТБ (HA)
16 ТБ/Не ограничено (HA)
Централизованное управление
StarWind Console
StarWind Console
StarWind Console
StarWind Console
Число серверов, входящее в лицензию
2
2 или 3
2 или 3
2 или 3
Число одновременных соединений по iSCSI к хранилищам
Из таблицы видно, что бесплатная версия StarWind Native SAN for Hyper-V Free edition практически ничем не отличается от платной, кроме ограничения на размер отказоустойчивого хранилища в 128 ГБ. Полное сравнение платного и бесплатного изданий StarWind Native SAN for Hyper-V доступно по этой ссылке.
Мы уже не раз затрагивали тему vswp-файлов виртуальных машин (файлы подкачки), которые используются для организации swap-пространства гипервизором VMware ESXi. Эти файлы выполняют роль последнего эшелона среди техник оптимизации памяти в условиях недостатка ресурсов на хосте. Напомним, что в гипервизоре VMware ESXi есть такие техники как Transparent Page Sharing, Memory Ballooning, a также Memory Compression, которые позволяют разбираться с ситуациями нехватки памяти, необходимой виртуальным машинам.
Напомним также, что первым эшелоном оптимизации памяти является техника Memory Ballooning. Она работает за счет использования драйвера vmmemctl.sys (для Windows), поставляемого вместе с VMware Tools. Он позволяет "надуть" шар внутри гостевой ОС (balloon), который захватывает физическую память, выделенную этой ОС (если ее много), и отдает ее другим гостевым операционным системам, которые в ней нуждаются. Этот balloon не позволяет гостевой ОС производить работу приложений с данной областью памяти, поэтому если им потребуется дополнительная память - она будет уходить в гостевой своп. Это более правильный подход, чем свопировать гостевую ОС в файл подкачки vswp на томе VMFS, поскольку операционная система сама лучше разбирается, что и когда ей класть и доставать из свопа (соответственно, быстродействие выше).
Однако, когда памяти у всех виртуальных машин совсем мало или отдельной ВМ ее требуется больше, чем сконфигурировано, а также происходит постоянное обращение к памяти (особенно, если в гостевых ОС нет VMware Tools), гипервизор начинает использовать vswp-файл подкачки, который по умолчанию находится в папке с виртуальной машиной. Мы уже писали о том, что в целях повышения быстродействия можно положить vswp-файлы виртуальных машин на локальные SSD-хранилища серверов ESXi, а также о том, как удалять мусорные файлы vswp.
Ниже мы приведем 8 фактов о swap-файлах виртуальных машин, которые основаны на вот этой заметке Фрэнка Деннемана:
1. Хранение vswp-файлов на локальных дисках сервера ESXi (в том числе Swap to Host Cache) увеличивает время vMotion. Это очевидно, так как приходится копировать vswp-файл в директорию ВМ (или другую настроенную директорию), чтобы его видел целевой хост.
2. С точки зрения безопасности: vswp-файл не чистится перед созданием. То есть там лежат не нули, а предыдущие данные блоков. Напоминаем, что размер файла подкачки равен размеру сконфигурированной памяти ВМ (если не настроен Reservation). Если же у машины есть Reservation, то размер vswp-файла определяется по формуле:
То есть, если в настройках памяти машины ей выделено 4 ГБ, а Reservation настроен в 1 ГБ, то vswp-файл будет составлять 3 ГБ.
3. Как происходит копирование vswp-файла при vMotion? Сначала создается новый vswp-файл на целевом хосте, а потом копируются только swapped out страницы с исходного в целевой vswp-файл.
4. Что происходит при разнице в конфигурации размещения vswp-файлов в кластере и для отдельных хостов? Напомним, что в настройках кластера VMware vSphere есть 2 опции хранения vswp-файлов: в папке с ВМ (по умолчанию) и в директории, которая указана в настройках хоста:
Если на одном хосте настроена отдельная директория для vswp, а на другом нет (то есть используется папка ВМ), то при vMotion такой виртуальной машины vswp-файл будет скопирован (в папку с ВМ), несмотря на то, что целевой хост видит эту директорию на исходном.
5. Обработка файлов подкачки при нехватке места. Если в указанной директории не хватает места для свопа ВМ, то VMkernel пытается создать vswp-файл в папке с ВМ. Если и это не удается, то виртуальная машина не включается с сообщением об ошибке.
6. vswp-файл лучше не помещать на реплицируемое хранилище. Это связано с тем, что используемые страницы памяти, находящиеся в двух синхронизируемых файлах, будут постоянно реплицироваться, что может вызывать снижение производительности репликации, особенно если она синхронная и особенно при vMotion в недефолтной конфигурации (когда происходит активное копирование страниц и их репликация):
7. Если вы используете снапшоты на уровне хранилищ (Datastore или LUN), то лучше хранить vswp-файлы отдельно от этих хранилищ - так как в эти снапшоты попадает много ненужного, содержащегося в своп-файлах.
8. Нужно ли класть vswp-файлы на хранилища, которые развернуты на базе thin provisioned datastore (на уровне LUN)? Ответ на этот вопрос зависит от того, как вы мониторите свободное место на тонких лунах и устройствах своего дискового массива. При создании vswp-файла VMkernel определяет его размер и возможность его создания на уровне хоста ESXi, а не на уровне устройства дискового массива. Поэтому если vswp-файл активно начнет использоваться, а вы этого не заметите при неправильной конфигурации и отсутствии мониторинга тонких томов - то могут возникнуть проблемы с их переполнением, что приведет к сбоям в работе ВМ.
Невозможно ощутить все преимущества виртуализации, не имея систему хранения данных. В рамках данного семинара мы расскажем, почему СХД NetApp наилучшим образом подходит для построения виртуальной инфраструктуры:
Мы уже писали о новых возможностях продукта номер 1 для создания откзоустойчивых хранилищ виртуальных машин StarWind iSCSI SAN & NAS 6.0, а также анонсировали вебинар "Что нового в версии 6.0", который прошел 24 октября. Для тех, кто пропустил это мероприятие, компания StarWind выложила запись этого вебинара на русском языке, который традиционно ведет наш коллега Анатолий Вильчинский.
Мы уже писали о том, что компания Veeam анонсировала скорую доступность решения номер 1 для резервного копирования и репликации виртуальных машин - Veeam Backup and Replication 6.5. Ожидается, что новая версия продукта будет выпущена в 4-м квартале этого года.
А пока пользователи ожидают новой версии продукта, компания Veeam выпустила документ "Veeam Backup & Replication What’s New in 6.5 Sneak Peek", из которого можно узнать о его новых возможностях. Итак, что же нового появится в новой версии B&R:
E-discovery and item recovery for Exchange Version 6.5 - в новой версии появился полнофункциональный Veeam Explorer for Exchange - технология поиска, просмотра и восстановления объектов (писем, папок, пользователей) из резервных копий почтовых серверов Exchange Server 2010. Делать это можно с резервными копиями ВМ, их репликами, а также снапшотами HP StoreVirtual VSA и LeftHand.
Restore from SAN snapshots - появилась технология Veeam Explorer for SAN Snapshots (пока только для хранилищ HP), которая поддерживает гранулярное восстановление виртуальных машин напрямую из снапшотов, сделанных устройствами хранения HP StoreVirtual VSA и HP LeftHand. Эта технология разработана совместно с HP и поддерживает все функции Veeam: Instant VM Recovery, Instant File-Level Recovery и Explorer for Exchange item recovery.
Поддержка VMware vSphere 5.1 - новая версия продукта полностью поддерживает обновленную платформу виртуализации, а также резервное копирование и репликацию виртуальных машин с гостевыми ОС Windows Server 2012 и Windows Server 8.
Полная поддержка функций Windows Server 2012 Hyper-V - Veeam Backup & Replication 6.5 поддерживает следующие возможности для Hyper-V:
Changed block tracking для томов CSV v2 и SMB v3
Поддержка формата виртуальных дисков VHDX
Поддерка больших дисков до 64 ТБ
Также Veeam Backup может быть использован для миграции на новую версию Hyper-V - можно создать резервные копии ВМ на Hyper-V 2008 R2 и восстановить их на Hyper-V 2012
Advanced monitoring, reporting and capacity planning - теперь, за счет еще более тесной интеграции с продуктом Veeam One в составе пакета продуктов Veeam Management Suite, решение Veeam B&R в составе позволяет выполнять следующие задачи:
Мониторинг инфраструктуры резервного копирования в реальном времени
Идентификация незащищенных виртуальных машин
Анализ доступных ресурсов, хранилищ и многое другое
Множество нововведений и улучшений: среди них можно отметить поддержку механизма дедупликации в Windows Server 2012, возможность резервного копирования конфигурации самого Veeam Backup and Replication, улучшения производительности и уменьшение потребления ресурсов, а также возможность восстановления файлов в гостевую ОС в их оригинальное размещение в один клик. Обо всех дополнительных нововведениях можно прочитать в первоисточнике.
Завтра, в 16-00 по московскому времени, Анатолий Вильчинский, системный инженер StarWind Software, проведет для вас интересный вебинар "Что нового в версии 6.0".
Не часто выпадает возможность послушать на русском языке о новой версии продукта от вендора. Поэтому регистрируйтесь и приходите.
О новых возможностях продукта StarWind iSCSI SAN & NAS 6.0 можно прочитать у нас тут.
Таги: StarWind, Webinar, Storage, iSCSI, SAN, NAS, HA
Компания StarWind, производитель решения номер 1 - StarWind iSCSI SAN, которое предназначено для создания отказоустойчивых iSCSI-хранилищ для платформ виртуализации VMware vSphere и Microsoft Hyper-V, объявила о начале новой промо-акции. Как вы знаете, недавно вышла финальная версия продукта StarWind iSCSI SAN 6.0, которая позволяет строить трехузловые кластеры непрерывной доступности хранилищ, которые экономически и технически более целесообразны, чем двух узловые.
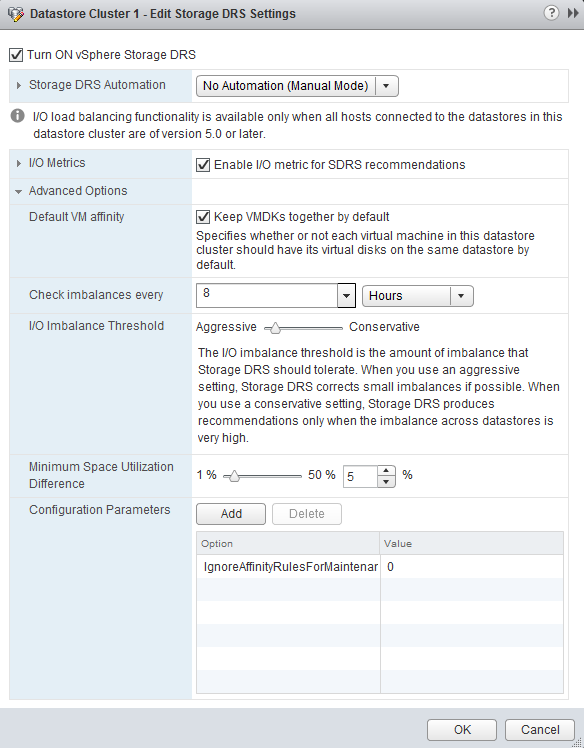
Не так давно мы писали про то, как работает механизм динамического выравнивания нагрузки на виртуальные хранилища VMware Storage DRS. Напомним, что он работает на базе 2-х параметров хранилищ:
Заполненность - в этом случае SDRS выравнивает виртуальные машины для равномерного заполнения хранилищ.
Производительность - при использовании этих метрик SDRS старается динамически перенести виртуальные машины с более нагруженных по параметрам ввода-вывода хранилищ на менее загруженные.
Однако бывает так, что несколько виртуальных хранилищ (Datastores) располагаются на одних и тех же RAID-группах, а значит миграция хранилищ виртуальных машин между ними ничего не даст - суммарно бэкэнд-диски системы хранения будут испытывать ту же самую нагрузку.
Например, бесполезна (с точки зрения производительности) будет миграция с Datastore1 на Datastore2:
Раньше этот факт не учитывался механизмом SDRS в vSphere 5.0, что приводило к бесполезным миграциям в автоматическом режиме. Теперь ситуация изменилась к лучшему в версии vSphere 5.1.
Как многие знают, в VMware vSphere есть механизм Storage IO Control (SIOC), который позволяет измерять мгновенную производительность хранилищ (параметр latency - задержка команд ввода-вывода) и регулировать очередь HBA-адаптеров на хостах ESXi. Так вот, одна из техник SIOC Injection позволяет производить тестирование виртуальных хранилищ на наличие корреляции производительности между ними.
Делается это следующим образом: SIOC запускает тестовую рабочую нагрузку на случайно выбранном Datastore1, измеряет latency, а потом отдельно от него запускает нагрузку на другом Datastore2 и также смотрит на latency:
Это нужно для установления базового уровня производительности для этих виртуальных хранилищ. Потом SIOC запускает нагрузку одновременно на 2 этих хранилища и смотрит, что происходит с latency:
Если оба этих хранилища физических расположены на одних и тех же дисковых устройствах (как в нашем случае), то измеряемые latency в данном случае возрастут, что говорит о взаимной корреляции данных хранилищ в плане производительности.
Узнав про этот факт, Storage DRS не будет генерировать рекомендации по перемещению виртуальных машин между хранилищами Datastore1 и Datastore2:
Однако эти рекомендации перестанут генерироваться только на базе производительности, на базе заполненности хранилищ такие рекомендации останутся.
Компания Citrix обновила свою бесплатную серверную платформу виртуализации, выпустив продукт Citrix XenServer 6.1, известный под кодовым названием "Tampa" (о версии 6.0 мы писали вот тут). Новая версия платформы была выпущена в начале октября, спустя почти год с момента прошлого релиза и имеет несколько новых возможностей, касающихся организации облачных инфраструктур. По словам сотрудников Citrx - это "cloud centric" релиз.
Новые возможности Citrix XenServer 6.1:
Улучшенная интеграция с облачными платформами - Citrix сделала множество улучшений для облачной инфраструктуры Apache CloudStack и Citrix CloudPlatform (на базе той же Apache CloudStack), включая улучшенные средства управления сетевым экраном, балансировки нагрузки Source Load Balancing (SLB), а также безопасности и предотвращения вторжений. Появилась поддержка LACP 802.3ad, тиминга 4-х NIC в конфигурации active/active, а также технологии switch-port locking для предотвращения спуфинга MAC и IP-адресов. Также теперь поддерживается до 150 виртуальных машин на хост XenServer. Обновился и Open vSwitch до версии 1.4.2.
"Shared Nothing" Storage Migration - возможность горячей миграции виртуальных машин между хостами и хранилищами, которые располагаются на локальных дисках серверов или раздельных для хостов хранилищах, т.е. не имеющих общего хранилища. Делается это средствами технологии Storage XenMotion, которая работает как внутри пулов XenServer, так и между ними.
Пакетная конвертация виртуальных машин с платформы VMware vSphere на XenServer - с помощью продукта XenServer Conversion Manager на базе отдельного виртуального модуля (Virtual Appliance) теперь можно организовать массовую миграцию с инфраструктуры VMware на XenServer для тех компаний, которым поддерживать среду vSphere стало слишком дорого.
Горячая миграция для VDI-образов - горячая миграция хранилищ виртуальных машин в VDI-формате виртуального диска без простоя.
Изменения XenServer Tools - теперь этот пакет для гостевой ОС поставляется в MSI-формате, что позволяет более гибко управлять его установкой в гостевых ОС.
Emergency Network Reset - возможность отката сетевой конфигурации хостов XenServer к последней работающей конфигурации.
VLAN Scalability improvements - улучшенные средства по настройке VLAN в пулах XenServer.
Об остальных незначительных нововведениях XenServer 6.1 (типа поддержки 4-х GPU Pass-through) можно почитать вот тут.
Также появилась поддержка следующих гостевых ОС:
Ubuntu 12.04
CentOS 5.7, 6.0, 6.1, 6.2
Red Hat Enterprise Linux 5.7, 6.1, 6.2
Oracle Enterprise Linux 5.7, 6.1, 6.2
Windows 8 (32-bit/64-bit) – экспериментальная поддержка
Windows Server 2012 –экспериментальная поддержка
Про новый продукт XenServer Conversion Manager:
Руководство по использованию продукта XenServer Conversion Manager можно посмотреть вот тут.
Скачать бесплатный Citrix XenServer 6.1 можно по этой ссылке. Документация доступна тут.
Компания StarWind, известная своим решением номер 1 для создания отказоустойчивой инфраструктуры хранения виртуальных машин для платформы Hyper-V - StarWind Native SAN, выпустила интересный документ, понятно объясняющий превосходство своего продукта над аналогами, существующими на рынке:
Если говорить кратко, то все эти преимущества вытекают из архитектуры решения, которая построена на базе всего 2-х узлов, которые одновременно являются кластером хост-серверов и кластером хранилищ:
А это значит, что:
Это не требует затрат на приобретение дополнительного узла хранилища.
Более надежно - при отказе одного из узлов виртуальные машины продолжат без простоя работать на втором.
Более производительно - операции чтения идут сразу с локального диск узла, а операции записи могут использовать высокопроизводительный кэш.
Frank Denneman опять написал интересную статью. Оказывается у механизма VMware Storage DRS, который производит балансировку виртуальных машин по хранилищам кластера SDRS, есть механизм задания допустимого уровня over-commitment для хранилища при миграции ВМ на тонких дисках.
Как вы знаете, у тонких VMDK-дисков (Thin Disks) виртуальных машин есть 2 параметра:
Provisioned Space - максимальный размер VMDK-файла, до которого может вырости диск виртуальной машины.
Allocated Space - текущий размер растущего VMDK-диска.
Разность этих двух парметров есть значение IdleMB, отражающее объем, на который виртуальный диск еще может вырасти. В расширенных настройках Storage DRS можно задать параметр PercentIdleMBinSpaceDemand, который определяет, сколько процентов от IdleMB механизм SDRS прибавляет к Allocated Space при выдаче и применении рекомендаций по размещению виртуальных машин на хранилищах кластера.
Рассмотрим на примере. Пусть максимальный размер диска VMDK составляет 6 ГБ при Allocated Space в 2 ГБ. Допустим мы задали PercentIdleMBinSpaceDemand = 25%. Тогда мы получим такую картину:
Таким образом, при размещении виртуальной машины на хранилище механизм Storage DRS будет считать, что ВМ занимает не 2 ГБ дискового пространства, а 2+0.25*4 = 3 ГБ. Ну и увидев такую машину на 10 ГБ-хранилище, механизм SDRS, при расчете выравнивания хранилищ по заполненности, будет считать что она занимает 3 ГБ, и свободно осталось лишь 7 ГБ.
Регулируя эту настройку можно добиться различных коэффициентов консолидации тонких VMDK-дисков машин на хранилищах. Ну и очевидно, что значение параметра PercentIdleMBinSpaceDemand равное 100% приведет к тому, что тонкие диски при размещении будут учитываться как их обычные flat-собратья.
Не так давно мы уже писали о новой версии решения для создания отказоустойчивых хранилищ для серверов VMware vSphere - StarWind iSCSI SAN & NAS 6.0. Одной из ключевых новых возможностей продукта является возможность создания треузловых кластеров хранилищ, которые более эффективны с экономической точки зрения, чем двухузловые.
Компания StarWind со своим продуктом прошла в финалисты конкурса "Storage, Virtualization & Cloud Awards", который отмечает заслуги производителей ПО в сфере хранения данных, виртуализации и облачных вычислений, в категории "Storage Software Product of the Year". Профиль компании StarWind на конкурсе можно посмотреть по этой ссылке.
Проголосовать нужно до 17 октября. Поддержите практически отечественного производителя, делающего реальные продукты, а не надувающих пузыри из соплей в Сколково!
Мы уже писали о том, что у компании StarWind есть бесплатный инициатор FCoE - для доступа к хранилищам данных Fibre Channel через сеть передачи данных Ethernet. Это позволяет использовать СПД 10G при сохранении протокола FC.
Этот инициатор позволяет получить доступ к любому iSCSI Target и подключить его хранилища как локальные диски, при этом работает он быстро и без ошибок, поскольку компания StarWind, которая уже много лет занимается протоколом iSCSI, знает в нем толк.
Не так давно мы уже писали о технологии виртуальных томов vVOL, представленной на VMworld 2012, которая позволит дисковым массивам и хостам оперировать с отдельными виртуальными машинами на уровне логического дискового устройства, реализующего их хранилище, что повысит производительность и эффективность операций с ВМ.
Там же, на VMworld 2012, компания VMware представила технологию vSAN, реализующую распределенное хранение данных ВМ на локальных хранилищах хост-серверов VMware ESXi (Distributed Storage):
Концепция vSAN, включающая в себя Distributed Storage, является продолжением существующего подхода к организации общих хранилищ виртуальных машин на базе локальных дисков серверов - VMware vStorage Appliance. Работает это средство обеспечения отказоустойчивости хранилищ за счет полного дублирования хранилищ одного из узлов кластера, а также репликации данных между ними:
Теперь же, в скором времени в гипервизор VMware ESXi будет включена технология Distributed Storage, которая позволит агрегировать вручную или автоматически дисковые емкости (HDD и SSD) хост-серверов в единый пул хранения с функциями отказоустойчивости и кэширования:
Разрабатывается эта концепция на волне распространения SSD-накопителей в серверном оборудовании и СХД. Единый пул хранения кластера Distributed Storage будет не только объединять диски серверов (туда добавляются диски без созданных разделов с определенным администратором вкладом емкости в общий пул) и предоставлять пространство хранения виртуальным машинам на любом из хостов, но и будет управляем средствами политик механизма Policy-Based Storage Management. Интересно то, что размер кластера хранилища для Distributed Storage будет равен размеру кластера хостов (сейчас 32), в рамках которого все хосты имеют возможность использовать агрегированную емкость пула, даже те серверы, что не имеют дисков вовсе.
Все это будет интегрировано с механизмами HA, vMotion и DRS в целях обеспечения отказоустойчивости и балансировки нагрузки на хост-серверы. Кроме этого, агрегированный пул хранилищ будет поддерживать все основные технологии VMware для работы с хранилищами: снапшоты ВМ, связанные клоны, vSphere Replication (vR) и vStorage APIs for Data Protection (vADP).
С точки зрения политик хранения, Distributed Storage будет предоставлять следующие варианты для каждой виртуальной машины:
Доступная емкость и объем ее резервирования.
Уровень отказоустойчивости (степень дублирования данных на узлах = количество реплик).
Уровень производительности (какое количество SSD-кэша выделить для обслуживания реплик, а также число страйпов для диска ВМ, если необходимо).
Данные в кластере VMware Distributed Storage хранятся на локальных дисках узлов по схеме RAID-1, так как это дает максимальный экономический эффект с точки зрения затрат на 1 IOPS при условии комбинирования HDD-хранилищ данных и SSD-хранилищ кэша и данных (подробнее тут). SSD-кэш работает как фронтэнд для HDD-дисков, обрабатывая кэширование чтений и буферизацию записи для операций кластера, при этом сделано множество оптимизаций кэша для увеличения вероятности попаданий в кэш при чтении данных ВМ с дисков различных узлов.
Ну а на практике vSAN уже работает в лабораториях VMware, где инженеры демонстрируют возможности Distributed Storage:
Информации о времени доступности технологии VMware Distributed Storage пока нет. Возможно, базовые функции vSAN будут реализованы в VMware vSphere 6.0.
Не так давно мы уже писали о новой версии решения для создания отказоустойчивых хранилищ для серверов VMware vSphere - StarWind
iSCSI SAN & NAS 6.0. Одной из ключевых новых возможностей продукта является возможность создания треузловых кластеров хранилищ, которые более эффективны с экономической точки зрения, чем двухузловые.
В этой заметке мы приведем доступные издания StarWind
iSCSI SAN & NAS 6.0. Издание StarWind CDP - это просто iSCSI Target, без функций высокой надежности, которое обеспечивает защиту данных только средствами снапшотов. Издания High Availability - это полнофункциональные версии продукта, одинаковые по функционалу, но различающиеся лицензируемой емкостью хранилищ.
Возможности StarWind
iSCSI SAN & NAS 6.0:
Издание StarWind CDP
Издания High Availability
Назначение
Средний и малый бизнес
Малый бизнес
Средний бизнес
Крупный бизнес
Компоненты продукта
Доступная емкость хранилищ
Не ограничена
1ТБ/2ТБ/4TB/8ТБ
16ТБ/32ТБ/64ТБ
128ТБ/256ТБ/512ТБ
Централизованное управление
StarWind Console
StarWind Console
StarWind Console
StarWind Console
Число узлов, включенное в лицензию
1
2/3
2/3
2/3
Число одновременных iSCSI-соединений
Не ограничено
Не ограничено
Не ограничено
Не ограничено
Число Ethernet-портов
Не ограничено
Не ограничено
Не ограничено
Не ограничено
Число обслуживаемых физических и виртуальных дисков
Как знают многие пользователи, среди новых возможностей VMware vSphere 5.1 есть так называемая Enhanced vMotion или "Shared-Nothing" vMotion - функция, позволяющая переместить работающую виртуальную машину на локальном хранилище ESXi на другой хост и хранилище с помощью комбинации техник vMoton и Storage vMotion в одной операции. Это означает, что для такого типа горячей миграции не требуется общее хранилище (Shared Storage), а значит и затрат на его приобретение. Напомним также, что функция Enhanced vMotion включена во все коммерческие издания VMware vSphere, кроме vSphere Essentials.
Давайте посмотрим поближе, как это все работет:
Сначала приведем требования и особенности работы vMotion при отсутствии общего хранилища:
Хосты ESXi должны находиться под управлением одного сервера vCenter.
Хосты должны находиться в одном контейнере Datacenter.
Хосты должны быть в одной Layer 2 подсети (и, если используется распределенный коммутатор, на одном VDS).
Enhanced vMotion - это исключительно ручной процесс, то есть функции DRS и Storage DRS не будут использовать миграцию машин без общего хранилища. Это же касается и режима обслуживания хоста (Maintenance Mode).
Для одного хоста ESXi может быть проведено не более 2-х Enhanced vMotion единовременно. Таким образом, на хост ESXi может одновременно приходиться максимум 2 штуки Enhanced vMotion и 6 обычных vMotion (всего 8 миграций на хост) + 2 операции Storage vMotion, либо 2 Enhanced vMotion (так как это также задействует Storage vMotion). Подробнее об этом тут.
Enhanced vMotion может проводить горячую миграцию одновременно по нескольким сетевым адаптерам хоста ESXi, если они имеются и настроены корректно.
Миграция Enhanced vMotion может быть проведена только через тонкий клиент vSphere Web Client (в обычном клиенте эта функция недоступна - см. комментарии):
Миграция Enhanced vMotion идет по обычной сети vMotion (а не по Storage Network), по ней передаются и диск ВМ, и ее память с регистрами процессора для обеспечения непрерывной работоспособности виртуальной машины во время миграции:
Теперь как это все работает последовательно. Сначала механизм Enhanced vMotion вызывает подсистему Storage vMotion, которая производит копирование данных по сети vMotion. Здесь важны 2 ключевых компонента - bulk copy и mirror mode driver.
Сначала механизм bulk copy начинает копирование блоков данных с максимально возможной скоростью. Во время этого часть блоков на исходном хранилище хоста может измениться - тут и вступает в дело mirror mode driver, который начинает поддерживать данные блоки на исходном и целевом хранилище в синхронном состоянии.
Mirror mode driver во время своей работы игнорирует те блоки исходного хранилища, которые меняются, но еще не были скопированы на целевое хранилище. Чтобы поддерживать максимальную скорость копирования, Mirror mode driver использует специальный буфер, чтобы не использовать отложенную запись блоков.
Когда диски на исходном и целевом хранилище и их изменяющиеся блоки приходят в синхронное состояние, начинается передача данных оперативной памяти и регистров процессора (операция vMotion). Это делается после Storage vMotion, так как страницы памяти меняются с более высокой интенсивностью. После проведения vMotion идет операция мгновенного переключения на целевой хост и хранилище (Switch over). Это делается традиционным способом - когда различия в памяти и регистрах процессора весьма малы, виртуальная машина на мгновение подмораживается, различия допередаются на целевой хост (плюс переброс сетевых соединений), машина размораживается на целевом хосте и продолжает исполнять операции и использовать хранилище с виртуальным диском уже целевого хоста.
Ну а если вы перемещаете виртуальную машину не между локальными дисками хост-серверов, а между общими хранилищами, к которым имеют доступ оба хоста, то миграция дисков ВМ идет уже по Storage Network, как и в случае с обычным Storage vMotion, чтобы ускорить процесс и не создавать нагрузку на процессоры хостов и сеть vMotion. В этом случае (если возможно) будет использоваться и механизм VAAI для передачи нагрузки по копированию блоков на сторону дискового массива.
Вместе с обновленной версией решения компания StarWind выпустила также ROI-калькулятор для расчета экономии денег на покупке хранилищ за счет механизма StarWind Global Deduplication.
Для 100-гиговых дисков виртуальных машин VMware vSphere получается экономия в 84%:
В качестве исходных параметров можно выбирать не только виртуальные машины, но и другие типы хранилищ физических серверов:
Доступен также выбор типа дисков (включая SSD) и используемого уровня RAID. Посчитать экономию за счет дедупликации StarWind можно здесь.
Партнеры и клиенты компании NetApp знают, что у нее есть виртуальный модуль (Virtual Appliance), который позволяет создавать общие хранилища для виртуальных машин VMware vSphere, называемый NetApp ONTAP Simulator. Это средство может предоставлять доступ виртуальных машин к дисковым ресурсам хост-сервера ESXi по протоколам iSCSI и NFS.
Теперь продукт Data ONTAP Edge доступен для всех желающих, а не только для партнеров и клиентов NetApp:
Основным вариантом использования Data ONTAP Edge компания NetApp видит его применение в удаленных офисах и филиалах организаций, которые не хотят делать больших инвестиций в дорогостоящие системы хранения данных.
Максимально поддерживаемый объем локальных хранилищ хост-серверов ESXi теперь составляет 5 ТБ вместо 20 ГБ в предыдущих версиях продукта. ONTAP Edge работает на платформе ONTAP 8.1.1 (ОС Data ONTAP-v) и требует не менее 2 vCPU для ВМ с виртуальным модулем, 4 ГБ памяти и не менее 57.5 ГБ дискового пространства. В решении поддерживается следующая функциональность, присущая оборудованию NetApp:
Snapshots
Replication
Deduplication
SnapVault
SnapMirror
SnapRestore
FlexClone
Поддержка программных интерфейсов VMware: VAAI, VACI и VADP
Поскольку данное решение не обладает функциями высокой доступности, то его пока можно использовать для тестирования и ознакомления с функциональностью продуктов NetApp. Можно также рассмотреть вариант его совместного использования с продуктами VMware VSA или StarWind iSCSI SAN, которые предоставляют функции высокой надежности и непрерывной доступности хранилищ.
Для установки Data ONTAP Edge потребуется следующая аппаратная конфигурация сервера ESXi:
Минимум 1 процессор Quad core или 2 Dual core (64-bit Intel x86) 2.27 ГГц или быстрее
4 и более ГБ памяти (рекомендуется 8 ГБ и больше)
4 или более локальных дисков на сервере
Сетевая карточка Gigabit Ethernet
Аппаратный RAID с поддержкой энергонезависимого write cache
Важный момент, что для работы с виртуальным модулем NetApp не поддерживаются функции управления питанием хостов ESXi. Соответственно политику управления питанием на хосте нужно выставить как "High performance" или убедиться, что она определяется как "Not Supported".
Скачать пробную версию продукта NetApp Data ONTAP Edge на 90 дней можно по этой ссылке. Вам потребуется зарегистрироваться и ввести e-mail адрес не с публичным, а с корпоративным доменом. О том, как работать с виртуальным модулем, написано вот тут.
Одной из таких политик для хост-серверов ESXi в vGate R2 является политика безопасного удаления виртуальных машин, что подразумевает очистку виртуальных дисков VMDK на системе хранения при их удалении с тома VMFS. Это позволяет убедиться в том, что конфиденциальные данные, находившиеся на диске, будут недоступны для восстановления потенциальным злоумышленником, который, например, может находиться внутри компании и иметь доступ к содержимому томов VMFS через систему хранения данных или средства управления виртуальной инфраструктурой VMware vSphere.
Для выполнения операции надежного удаления ВМ администратор должен иметь доступ к ESXi-серверу (а именно к TCP-портам 902, 903, 443), на котором выполняется удаляемая ВМ, а также иметь привилегию "разрешено скачивать файлы виртуальных машин".
Если для удаляемой ВМ задана соответствующая политика безопасности, очистка дисков виртуальных машин выполняется автоматически. Если политика не задана, для этого может использоваться специальная утилита командной строки vmdktool.exe. Утилита также может быть полезна в том случае, если была удалена не ВМ полностью, а
только какой-то ее диск.
Перед очисткой диска ВМ необходимо убедиться в отсутствии у виртуальной
машины снапшотов, после чего необходимо остановить ВМ.
В большой виртуальной инфраструктуре присутствуют сотни хранилищ VMFS, созданных поверх LUN, где лежат виртуальные машины с различным уровнем требуемого сервиса и политик. Проблемы начинаются с того, что система хранения не знает о том, что на ее LUN находятся виртуальные машины. Например, синхронная репликация на уровне массива может делаться только на уровне LUN, хотя с данного тома VMFS требуется реплицировать не все ВМ, которые могут быть с различным уровнем критичности. То же самое касается снапшотов и снапклонов уровня массива...
Одновременно с анонсом новой версии платформы VMware vSphere 5.1 компания VMware объявила об обновлении средства VMware vSphere Storage Appliance 5.1 (VSA), которое позвляет организовать общее отказоустойчивое хранилище для виртуальных машин на базе локальных дисков хост-серверов VMware ESXi с использованием двух или трех узлов. О новых возможностях VSA предыдущей версии (1.0) мы уже писали вот тут, а сегодня расскажем о новых возможностях и лицензировании версии 5.1.
Итак, что нового появилось в VMware vSphere Storage Appliance 5.1:
Максимально поддерживаемые характеристики локальных хранилищ серверов ESXi теперь таковы:
3 ТБ диски
8 дисков до 3 ТБ каждый в конфигурации RAID 6 (без hot spare)
18 ТБ полезной емкости под тома VMFS-5 на 1 хост
27 ТБ полезной емкости на 3 хоста
2 ТБ диски
12 локальных дисков до 2 ТБ в конфигурации RAID 6 (без hot spare)
16 внешних дисков до 2 ТБ в RAID 6 (вместе с hot spare)
VMware поддерживает максимальный размер тома VMFS-5 size до 24 ТБ на хост в VSA 5.1
36 ТБ полезной емкости на 3 хоста
Ранее, в VSA 1.0, установка vCenter не поддерживалась на хранилищах узлов, входящих в VSA-кластер. Теперь можно устанавливать vCenter на одно из локальных хранилищ серверов, не входящее в общее пространство VSA. В этом случае, при создании общей емкости VSA можно выставить размер общего пространства, оставив нужное место на локальном VMFS под vCenter:
Эта же возможность относится и к установке VSA на существующих хостах ESXi, где на локальных дисках уже есть виртуальные машины. Администратор сначала создает общее пространство VSA на хостах кластера, а потом с помощью Cold Migration переносит в общий том VMFS эти виртуальные машины. Освободившееся место можно присоединить к пространству VSA за счет функции увеличения емкости.
Емкость хранилищ VSA может быть увеличена на лету за счет добавления новых дисков. Можно добавить новый Extent к тому VMFS, а можно пересоздать RAID и сихнронизировать его с другим узлом кластера:
Также теперь с одного сервера vCenter можно управлять сразу несколькими кластерами VMware VSA, каждый из которых состоит из двух или трех узлов. Таких кластеров может быть до 150 штук для одного vCenter. Это хорошо подходит для организаций, имеющих распределенную инфраструктуру филиалов, где, как известно, денег на покупку общих систем хранения обычно нет (ROBO-сценарии).
Модуль VMware VSA 5.1 можно использовать для различных сценариев и всех изданий VMware vSphere 5, кроме самого низшего - Essentials:
Возможности продукта для всех изданий полностью идентичны, кроме того, что VSA for Essentials Plus не может управлять несколькими кластерами VSA, поскольку очевидно, что нужна лицензия vCenter Standard. Если же VSA 5.1 используется для Essentials Plus в конфигурации ROBO (то есть, несколько сайтов, объединенных единой точкой управления) - то так делать можно.
Кстати о лицензии на vCenter Standard - раньше для пользователей Essentials Plus она временно требовалась, когда вы заменяли один из узлов кластера. Теперь такой необходимости нет.

 RSS
RSS (128 ГБ)
(128 ГБ)




















































































{kind=link}

